Shibboleth Identity Provider 3 Clustering
Why clustering?
Like any Web application offered to the public, IdPs are supposed to "always" be available. There's a couple of techniques to increase availability, some of them named "Clustering", that we will discuss below.
First, let's have a look at the reasons why a service like the IdP may not be available. We may find reasons for downtimes like
- Hardware failures, like
- Server component failures
- Network failures
- Power failures
- ...
- Service overload
- Major upgrades
Note: It is important to verify that the chosen techniques actually have a positive impact on the potential reasons for a downtime, as these techniques may have their own costs.
If you are looking for alternatives to clustering techniques, while still increasing availability of the service using common sense techniques, you may stop reading after the next chapter.
How to avoid clustering
Hardware failures can be mitigated by installing the IdP application on a physical box which already has redundant components like
- redundant power supplies
- redundant disk arrays (RAID's)
- redundant network connectivity
- redundant memory
- ...
Whether or not to add a virtualization layer in between, is up to you. Virtualization has the advantage that these redundant components can be shared between several applications.
Below, we will see that ensuring availability of memory contents is usually hard, in particular when those contents should be saved away over a large physical distance. So, if there were a way to "pack" a whole VM in a "real" HA environment, we probably might want to consider this for the operation of IdP's.
IdP Specifics
Please start here. In short:
- Most often, statefulness is fact, as usually the login process goes through one or more views.
- This state - and a couple of other things - are usually represented in memory.
- Memory is - as we know - volatile. But we need the speed, and there's currently no way to make this state persistent (see the section about the Conversational state).
- We therefore usually give up caring about statefulness, and accept that a user may have to start over the login process in case of a server failure.
- Unlike "volatile" information, which can get lost when a server fails, we call a piece of information "persistent" if it's stored away on a nonvolatile device, most likely in a database, or just on disks.
- The "persistent ID" or rather "targeted ID" is a term used in the SWITCHaai context.
So, we are adjusting our target: In case one IdP isn't available, we accept that the users may have to start over their login process. But we still want that the whole service isn't affected as such, i.e. that it can serve new users. Before we look at the various options to implement this, we need to have a look at the various storage entities that are often handled in memory:
Here are the storage entities in question (in the SWITCHaai context):
- Targeted (or persistent) ID
- User Consent
- IdP User Session
- Transient ID (used on the backchannel)
- SAML artifact
- Conversation session
- Message replay cache
- Make these entities persistent by writing them into some nonvolatile database or on files
- Save the values of these entities in the browser on the client side
- Don't care, as these entities would have to be re-initialized anyway in case of a failure
- Targeted (or persistent) ID: Unlike in the default setup of the Shibboleth project, the targeted ID should in SWITCHaai always be stored in a nonvolatile database.
- User Consent: dito.
- IdP User Session: This value should be saved in the browser on the client side. Note: The data stored in the browser is encrypted. This requires that all nodes share a common encryption key. See Secret key management for cookie encryption below for details.
- Transient ID: this value should also be stored in a nonvolatile database. Remember: The transient ID is used as reference when an SP does attribute querying, particularly with SAML1.1. In a redundant setup, the SP might connect to another node than the browser client.
- SAML artifact: dito.
- Conversation session: Don't care about this entity, as it would be re-initialized in case of a failure.
- Message replay cache: dito.
We don't refer to the corresponding configuration locations at this point... But based on these recommendations, we can now move to the planning of the redundant setup.
IdP Components, from a HA view
Two components of the IdP should be considered more thoroughly, that is the front end and the back end.The front end: redundancy on the network level
Should a web service like an IdP fail in a clean way, i.e. such that in particular the network interface properly goes down, then a high availability setup simply means that another server jumps in and continues to handle the incoming requests. This can be achieved in a couple of ways:
- Start up the slave, manually or even automatically. This requires that
- the route to the slave is drilled through the network, often by simply attaching the slave to the same router (which may introduce a couple of SPOF's in itself btw., see below)
- the slave is ready to take over the job on the network level. For this, the IP address can just be defined on the NIC, but enabled only in case of failover. Note: Taking over on a DNS level is usually not an option, as the TTLs are usually higher than the time one would allow the slave to jump in.
- Use some kind of a load balancer. However, this introduces a couple of things to think at on its own:
- Round robin is not your preferred choice, as this would ignore the conversational state between the client and the server it picked at the first contact. You may rather want to define some degree of stickyness (see below for an extended discussion).
- It shouldn't be made too sticky either, as the server the client picked at the first contact may go down as well, in which case the client should be sent to some other server after a reasonable amount of time, in order to start over.
The back end: redundancy on the data level
Taking over the job on the network level (see above) is necessary but not sufficient. The other main part cares about the state - as far as it can be saved away, i.e. apart from the conversational state discussed above. We basically know about the following techniques:
- Periodically copy the contents of the database of some master server to the slave, such that the slave can start at a consistent state in case of a failover.
- Build up a highly available data store, e.g. a database, on its own, and let the worker nodes, or the slave connect when appropriate.
- Instead of using a database system, or in order to complement a database system, one may use some more lightweight memory object caching system like memcached.
So, let's put the pieces together.
A typical first approach: add a second - standby - box
This type of clustering may also be called Master-Slave or Active-Passive standby. The basic idea is that the second box (the slave or the normally passive clone) would simply "take over" the work from the active or master box which usually just does the job.
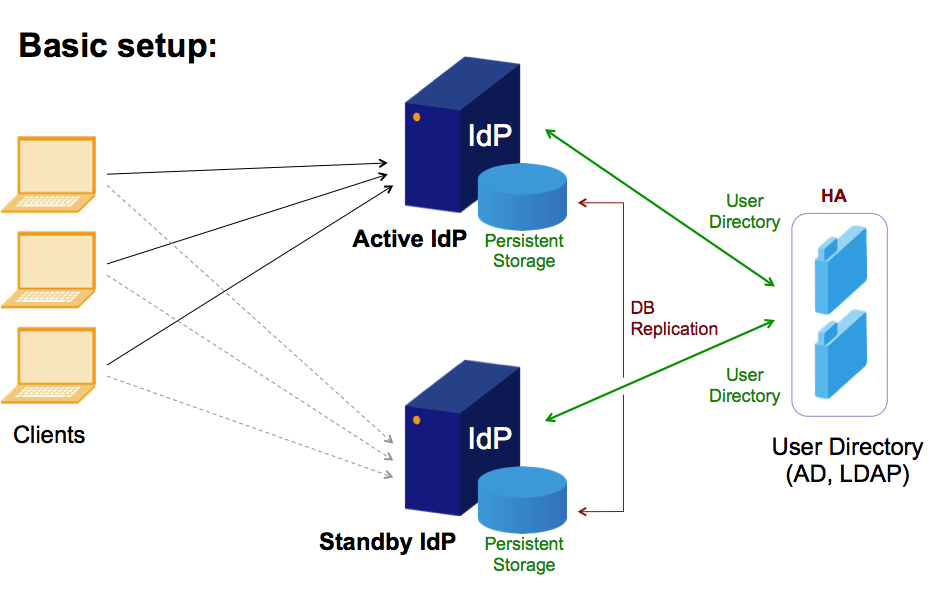
The following points should be carefully considered:
Preparation of the slave:
- On the network side: make sure that the slave can take over the IP address.
- On the data side: make sure that the data is periodically copied over. Make sure that the period is reasonably short, such that the data is reasonably up to date. Make sure that the data is always consistent, even in the case when the master dies in the middle of such a copy operation.
- Make sure that the slave has the proper software, patch level, etc. installed. You may want to monitor the slave as well, such that it is actually ready to take over at any time.
Initiate and commit proper failover
- Failover can be dangerous in itself. When you do a manual failover, you may want to make sure that the master is really down before you turn the slave on. If only parts of the master are down, one should first take it down completely. This also applies to automatic failover, which has then to be extended by a thorough monitoring of the master and eventually a definitive takedown (Example).
- After failover, the server should cease to try and copy the database over from the former master. Make sure that this operation doesn't harm any more.
Fail back?
Once the slave has taken over, and the master is gone, redundancy is also gone. You therefore may want to get the master back to normal operation as soon as possible. But wait, this may harm your service!
Before you turn your former master back on, you may want to think about how roles can now be switched (you may even think about this before a failover happens). In particular, the following points should be considered:
- If the master comes up and switches on the network interface with the public IP of the service, you will immediately have two servers claiming the same IP address on the network. This you may want to avoid.
- If the master pushed its data over to the slave on a regular basis, then you may want to prevent that before it comes up and scrambles your data.
The full featured approach: Load balancing, worker nodes and data store
This concept is often used for increasing the availability of services. It has separate solutions for the front end on the network side and the back end on the data side. In addition, adding worker nodes is easy and can increase overall performance.
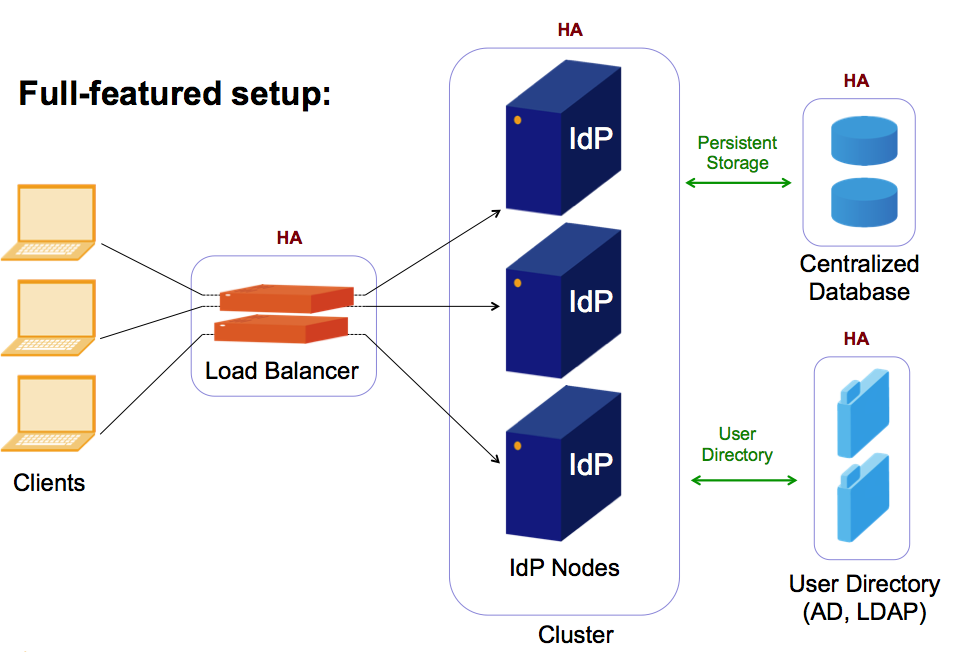
The following points should be carefully considered:
Session stickyness (again)
Load balancers can be configured to assign clients to worker nodes following a specific algorithm. For stateless services, the preferred algorithm is often round robin, as it usually yields a quite evenly distributed load over the worker nodes.
For services carrying a conversational state, this makes no sense at all, as the client connects again and again during the login process, and would again and again fall on another worker node that doesn't yet know about e.g. the message replay cache etc. (Unfortunately, the login process cannot be wrapped into one TCP session).
So the load balancers have to remember which worker node they assigned to which client in the recent past, where recent past is usually chosen in the range of the time needed to go through a login process. And, it is equally important that the load balancers forget about this assignment after this amount of time, as they would else assign failed worker nodes to clients over and over again.
Overall redundancy
If you think that the service is now set up in a higly available way, consider the following potential single points of failure (SPOF's):
- Network: Is there only one load balancer? If yes, you may want to put another one there. Think whether you prefer an active-passive or an active-active setup. In the active-passive setup make sure that the passive component can actually take over the task. In an active-active setup, think at how the two components can be configured such that they apply the same stickyness rules, i.e. send the same client to the same worker node.
- Network: Is there a redundant path to the router(s)? If no, you may want to think about redundant network topology.
- Database: Have you installed a database cluster? If no, you may want to think about removing this SPOF. Many database systems offer clustered operation. However, this increases complexity in its own. Postgres, the recommended database system for the IdP, may not be your first choice in that case.
- Further services: Is the LDAP or AD server on the back end also clustered? If no, you may want to talk to its administrator.
- Location: Is your hardware all installed in one location? If yes, you may want to think about splitting it up into two locations, such that either one may provide the whole service. Btw.: If you start doing that, you may also think about whether local redundancy like e.g. dual power supplies etc. is still needed.
Secret key management for cookie encryption
The IdP User Session is stored in an encrypted cookie in the browser. The key to encrypt/decrypt this cookie should regularly be rotated.
In a clustered setup, all nodes need to share the same key. It's recommended that one node generates a new key and copies it to the other nodes.
If you have setup the cronjob "idp-rotate-sealer" on your nodes, as described in section "Configuring periodic encryption key rotation" in the Shibboleth Identity Provider 3 Installation Guide, we recommend to adapt your setup as follows:
- Decide for a node that is responsible for generating the secret keys and copying them to the other nodes.
- On this node, adapt the script "/opt/shibboleth-idp/credentials/rotate-sealer.sh" as shown in the example below.
- On the other nodes, disable the existing cronjob "/etc/cron.d/idp-rotate-sealer".
Example adaptation of the script "/opt/shibboleth-idp/credentials/rotate-sealer.sh":
#!/bin/sh IDP_HOME=/opt/shibboleth-idp java -cp "$IDP_HOME/webapp/WEB-INF/lib/*" \ net.shibboleth.utilities.java.support.security.BasicKeystoreKeyStrategyTool \ --storefile $IDP_HOME/credentials/sealer.jks \ --versionfile $IDP_HOME/credentials/sealer.kver \ --alias secret \ --storepass "$(grep '^idp.sealer.password' $IDP_HOME/conf/credentials.properties | \ cut -d = -f 2)" scp $IDP_HOME/credentials/sealer.* host1:$IDP_HOME/credentials/ scp $IDP_HOME/credentials/sealer.* host2:$IDP_HOME/credentials/This implementation assumes that the node running the cronjob can access the other nodes per SSH. For security reasons, you may want to create a dedicated user on your systems that runs this script and copies the secret keys to the other nodes. (The setup of that is out of scope of this guide and is not described here.)
Examples
Several organizations have implemented their specific IdP clustering following their needs and according to their environment. We have seen the following implementations:
- NGINX as an HTTP load balancer in an active-active setup, with two IdP worker nodes and a MSSQL database cluster in the back end.
- An F5 BIG-IP load balancer, with JPA/JDBC storage on a MySQL database, and a Continuent Tungsten Replicator. In detail:
- The F5 BIG-IP load balancer has to distribute and failover connections (source IP sticky) for a pool of two IdP nodes and to just do failover for a pool of two MySQL database nodes (only one DB node is accessed until it fails).
- The IdP is configured so that user consent uses JPA/JDBC storage on a MySQL database, and persistentId storage uses the MySQL database. The IdP sessions are stored in the user browser session cookies.
- The Continuent Tungsten Replicator is installed in multi-master mode to replicate asynchronously each mysql database modification to the other one.
- A HW load balancer in an active-passive setup and an external MySQL-DB cluster based on Heartbeat and DRBD.
- Another NGINX load balancer with two IdPs behind, using memcached, and a single PostgresDB server in the back end.
- A (manual) failover installation based on an anycast address leading to two different locations in an active-passive-setup, with a local database which is replicated by a cron job to the slave, very similar to the basic setup described above.
References
Shibboleth Project Wiki: Clustering